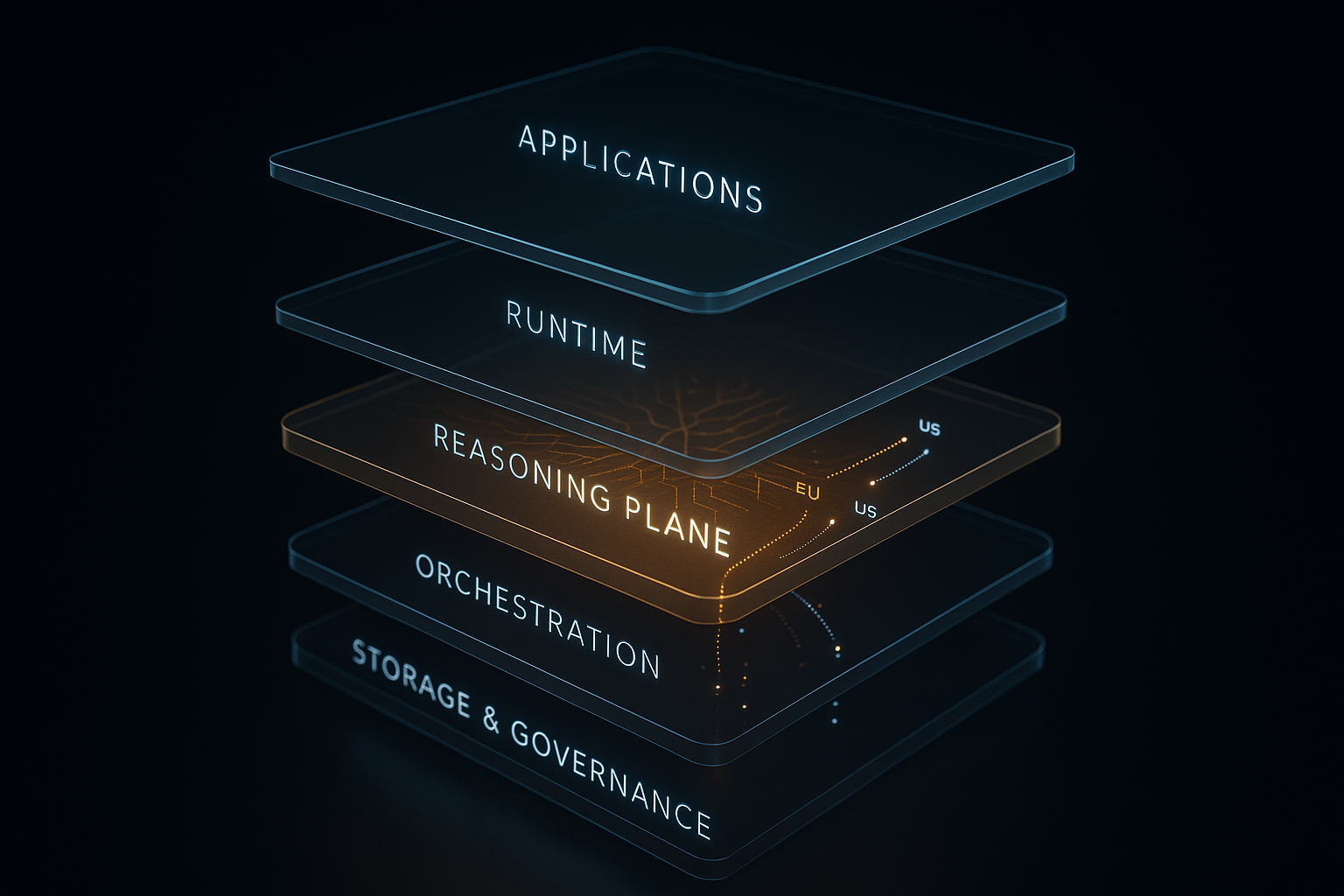
The CTO Advisor 4+1 Layer AI Infrastructure Model
A Reference Architecture for Composable Enterprise AI Systems
Executive Summary
Every vendor today claims to deliver an “AI Platform” or an “AI Operating System.” In reality, they’re describing different layers of an increasingly disaggregated ecosystem. The CTO Advisor 4+1 Layer AI Infrastructure Model was born not from theory, but from practice.
The DGX Realization: When I moved an AI application from the seamless abstraction of Google Cloud Platform (GCP) to a bare-metal NVIDIA DGX Spark, I hit a wall. The cloud had been operating an invisible Reasoning Plane—making autonomous decisions about where and how to run intelligence, decisions that transcended simple Kubernetes resource scheduling.
The move exposed what was missing: Layer 2C. While GCP provided implicit autonomy—Cloud Run handling auto-scaling based on load (cost/SLA optimization) and Vertex AI managing data access (avoiding egress)—the bare-metal deployment forced me to confront that these functions were nonexistent outside the cloud’s control plane.
The lesson: If you want the intelligence of a hyperscaler AI stack, you must explicitly define and build the Layer 2C Reasoning Plane.
This framework makes hyperscaler AI system architecture explicit and reproducible for enterprise environments. The goal: reclaim architectural clarity, close the AI delivery gap, and enable enterprises to build composable, performant, and governable AI environments.
1. The Four Foundational Layers of the Enterprise AI Stack
The +1 designation emphasizes that Layer 3 (Agent Applications) is the Value Plane; it consumes the lower layers to deliver business outcomes.
| Layer | Purpose | Representative Technologies | Primary Value |
|---|---|---|---|
| Layer 3: AI Application Layer (+1) | Deliver AI-powered business capabilities | LangGraph, CrewAI, Semantic Kernel, Custom Copilots | Business Logic, workflow automation |
| Layer 2C: Agentic Infrastructure | Policy-driven placement and resource coordination (The Autonomy Layer) | Kamiwaza Orchestration, Custom (OPA + Constraint Solver) | Autonomy, Policy Enforcement |
| Layer 2B: Application Runtime | Execute and coordinate AI workloads and service graphs | Ray, Vertex AI Pipelines, NVIDIA NIMs, KServe | Model Serving, workflow orchestration |
| Layer 2A: Infrastructure Orchestration | Govern & provision compute environments | Rafay, Run:ai, GKE Autopilot | GPU Scheduling, quotas, policy |
| Layer 1C: Data Movement & Pipelines | Move/transform data into governed stores & indexes | Dataflow, Fivetran, Airflow | ETL/ELT, lineage, cost-aware movement |
| Layer 1B: Context Management & Retrieval | Low-latency retrieval for RAG/features | Weaviate, pgvector, FAISS/ScaNN | Vector/hybrid search, context windows |
| Layer 1A: Data Storage & Governance | Durable, governed data foundation | VAST Data, Databricks, Snowflake Arctic | Lakehouse, governance, feature store |
| Layer 0: Compute & Network Fabric | Raw compute, networking, and acceleration fabric | NVIDIA DGX, AMD MI300, InfiniBand, Ethernet | Throughput, latency, capacity |
2. The Operational Tri-Plane: Orchestration, Runtime, and Reasoning
The operational core is split into three highly specialized planes. Layer 2C is the architectural differentiator that turns infrastructure capacity (2A) and model execution (2B) into an intelligent platform.
Layer 2A – Infrastructure Orchestration (Control Plane)
Role: Govern resource allocation and enforce static policy (quotas, RBAC, lifecycle).
Responsibilities:
- Provision and scale Kubernetes/GPU clusters
- Enforce quotas, namespaces, RBAC
- Optimize utilization and fair-share scheduling
- Surface telemetry to Layer 2C for autonomous decision-making
Example policy (enforced by Layer 2A, consumed by Layer 2C):
yamlapiVersion: v1
kind: ResourceQuota
metadata:
name: ml-team-financial-models
namespace: financial-ml
spec:
hard:
requests.nvidia.com/gpu: "16"This quota ensures the financial ML team cannot exceed 16 GPUs. Layer 2C respects this constraint when making placement decisions.
Layer 2B – Application Runtime & Execution (Execution Plane)
Role: Manage runtime execution, distributed inference, and model serving.
Responsibilities:
- Execute model inference and training workloads
- Orchestrate distributed RAG graphs and agent workflows
- Handle backpressure, retries, circuit breakers
- Expose inference APIs and service endpoints
- Report SLA metrics to Layer 2C
Layer 2C – Agentic Infrastructure (The Reasoning Plane)
Role: Act as an intelligent policy engine that makes autonomous placement decisions using business context (governance, cost, SLAs), not just cluster metrics. It enforces the Compute Moves to Data principle.
Technical Differentiation: Layer 2C vs. Traditional Orchestration
| Capability | K8s Operators (Layer 2A) | Layer 2C (Reasoning Plane) |
|---|---|---|
| Decision Input | Cluster state (CPU/GPU metrics) | Multi-dimensional: Cluster state + Data governance metadata + Cost policy + Latency SLO |
| Optimization | Single objective (utilization, queue depth) | Multi-objective (cost + latency + compliance) |
| Scope | Single cluster | Cross-cluster, hybrid, and edge environments |
Example Decision Algorithm (Layer 2C Placement):
# Layer 2C logic: Makes a multi-objective decision
data_meta = self.governance_catalog.get_metadata(workload_request.dataset_id) # Query Layer 1A
# Apply compliance filter
compliant_clusters = [c for c in clusters if self._satisfies_compliance(c, data_meta.compliance_tags)]
# Multi-objective optimization: minimizes cost/latency while satisfying constraints
best_cluster = self._optimize(
objectives=[minimize(cost), minimize(latency)],
constraints=[
lambda c: c.region == data_meta.data_residency, # Data Residency Rule
lambda c: c.available_gpu >= workload.required_gpu
])3. Data Plane: The Foundation for Context and Retrieval
The Data Plane (1A, 1B, 1C) serves as the context engine. Layer 1A (Storage & Governance) is the Governance Catalog that Layer 2C uses to make its decisions.
Example Governance Metadata (Layer 1A)
This is what Layer 2C queries from the governance catalog:
{
"dataset_id": "customer_orders_eu",
"classification": "PII",
"data_residency": "EU",
"retention_policy": "7_years",
"storage_endpoints": [
"s3://eu-central-1/customer-data"
],
"compliance_tags": {
"gdpr_compliant": true,
"data_classification": "Level_3"
},
"lineage": {
"source_system": "SAP_ERP",
"last_updated": "2024-10-29T08:00:00Z"
}
}This metadata drives Layer 2C placement decisions.
Example: How Layer 2C Enforces “Compute Moves to Data”
Scenario: European customer queries copilot about their order history.
- Layer 3 Request: Agent asks for customer data
- Layer 2C Reasoning: Intercepts the request and queries the Layer 1A Governance Catalog for the dataset metadata:
data_residency: "EU" - Placement Decision: Layer 2C instructs Layer 2A to provision the runtime only on available clusters in the EU region (eu-central-1)
- Execution: Inference runs entirely within the EU. The data never crossed borders.
Key enabler: Governance metadata (1A) became orchestration input (2C).
4. Layer 0: Compute & Network Fabric
The physical substrate: GPUs/TPUs/CPUs, interconnects, and offload. Networking is a first-class element that defines throughput and data locality.
5. Layer 3: The AI Application Layer (+1)
Layer 3 is the Value Plane where agents realize autonomous reasoning. It is the application logic that consumes the autonomy and policy enforcement provided by Layer 2C.
Division of Responsibility:
- Layer 3 (Agent Apps): Focuses on Application Logic (e.g., multi-step planning, memory management for a user)
- Layer 2C (Agentic Infra): Focuses on Infrastructure Logic (e.g., policy enforcement, global capacity management)
6. End-to-End Flow and Case Studies: The Tri-Plane in Action
The modern AI request flows Upward (Data & Context) from Layer 0 to 3, while Control (Policy & Orchestration) flows Downward from Layer 2C/2A to 0.
Case 1: The DGX Realization (Architectural Exposure of Layer 2C)
The vCTOA was successfully deployed on a managed environment (GCP Cloud Run, Vertex AI) where the Layer 2C function was implicit.
- Layer 2A/2B (Runtime/Orchestration) was handled by Cloud Run, providing seamless auto-scaling (load-based scaling is a form of cost/SLA optimization)
- Data Locality was implicitly managed by Vertex AI and Google Search Grounding, reducing the need for explicit egress controls
The attempt to define the stack for a bare-metal DGX Spark environment immediately exposed the missing Layer 2C. The realization: on-premise, I would have to manually build the logic to manage auto-scaling, enforce cost limits, and ensure the LLM workload runs near its data (GCS/Discovery Engine), validating that Layer 2C is the essential, missing component in traditional bare-metal AI infrastructure.
Case 2: CTO Signal Scanner (Layer 2C Function as Cost Governor)
The vCTOA architecture implements a critical cost-saving function via Conditional Grounding and Advisory Mode (disabling live search).
- L3 Agent Request: “Analyze this stream of articles”
- Decision Logic (Embedded in Layer 3): The Chat API (L3) executes the logic to switch between using the curated knowledge base (cheap) and invoking Google Search Grounding (expensive, L2B/External). This logic is structurally performing the cost governance function of Layer 2C.
- Impact: By pre-filtering content before invoking the expensive LLM/Search process (an optimization currently embedded in L3), the system achieved a 70% reduction in L2B (GPT) API calls—proving that this decision-making is the core autonomous cost governance that needs to be abstracted into Layer 2C.
This shows that in early-stage enterprise AI platforms, the core Layer 2C function often starts embedded within the Layer 3 application logic, waiting to be abstracted into its own dedicated reasoning plane for enterprise-wide use.
Case 3: The Town of Vail Smart City (Agentic Layer 2C in Action)
The HPE Agentic Smart City solution deployed in the Town of Vail uses the Kamiwaza orchestration platform as a direct, explicit implementation of Layer 2C (The Reasoning Plane). This deployment proves the architectural viability and speed of Layer 2C, moving from concept to four functional use cases in less than three months.
Layer 2C Functions Demonstrated:
1. Autonomous Governance and Security (ReBAC)
Kamiwaza’s ReBAC (Relationship, Attribute, Role-Based Access Control) security model is implemented at Layer 2C to ensure agents can only access data and tools within their authorized security context, even when sub-agents are involved. This is critical for cross-departmental use cases where a single agent (L3) may need to query data from multiple, siloed systems (L1A/B).
2. Compliance-Driven Policy Enforcement (508 Compliance)
The Agentic solution includes a use case for 508 compliance (accessibility for people with disabilities), which Vail has already implemented. The Layer 2C agent not only identifies areas for remediation but is able to perform those remediations (e.g., creating alt text for images, reading PDFs), with a human-in-the-loop review before posting. This demonstrates an agent autonomously enforcing a key governance policy, a core function of Layer 2C.
3. Cross-Silo Coordination and Multi-Objective Decision-Making (Fire Detection and Prevention)
Layer 2C orchestrates multiple Layer 2B models (Vision AI, Geospatial) and Layer 1C data feeds (NOAA, satellite imagery, moisture sensors) to analyze a potential fire incident. It uses a complex, multi-objective assessment (e.g., high timber rating + high home impact + Red Flag Day) to create a full report and urgency rating, which then dictates a multi-departmental workflow (notifying fire department, city planners, and reverse 911). This policy-driven, time-sensitive workflow is the essence of Layer 2C autonomy.
4. Compute-to-Data Locality
The Kamiwaza stack, running in Vail’s private data center, is designed to move the compute to the data. Its Inference Mesh and Distributed Data Engine scan all enterprise data, build a global data catalog (L1A), and redirect inference requests to the stack closest to the required data, ensuring security and low latency.
The Vail use case provides a clear, high-ROI example of Layer 2C’s ability to break down departmental silos with a unified agentic platform.
7. Common Failure Modes
Failure Mode 1: Skipping Layer 2C (The Critical Failure)
Symptom: Application team builds agent that directly calls 2A orchestration APIs.
What Breaks: GDPR Violation. Agent provisions GPU in US region, retrieves EU customer data, leading to PII compliance failure.
Fix: Implement a Layer 2C service mesh where all provisioning requests flow to enforce the if data_residency == "EU" then cluster.region must == "EU" rule.
Failure Mode 2: Telemetry Lag in 2C Decision Loop
Symptom: Layer 2C makes placement decisions based on 5-minute-old utilization data.
What Breaks: SLA Violation. 2C routes workload to an “idle” cluster that is actually at 95% utilization.
Fix: Migrate telemetry data consumption from pull-based (stale metrics) to push-based streaming with a maximum age limit (e.g., 1 second).
Failure Mode 3: Policy Oscillation Between 2A and 2C
Symptom: 2C (Reasoning) and 2A (Orchestration) policies conflict. 2C says “Scale up,” but 2A says “Quota exceeded, scaling down.”
What Breaks: Cost Spikes/Churn. Constant pod thrashing prevents workloads from completing.
Fix: Introduce hysteresis bands (e.g., stable zone: 65-85%) into the Layer 2C scaling logic to prevent rapid, conflicting decisions.
8. Decision Frameworks: Build vs. Buy
| Feature | Option 1: Build Your Own 2C | Option 2: Packaged 2C Platform (e.g., Kamiwaza) |
|---|---|---|
| Effort | 6-12 months, 2-3 engineers | 2-4 months implementation (Vail achieved use cases in <3 months) |
| Components | OPA/Kyverno (Policy), Custom Python/Constraint Solver (Placement), etcd (State) | Kamiwaza Orchestration, NVIDIA NeMo Guardrails, Ray on KubeRay + Custom Controller |
| Control | High (Custom algorithms) | Medium (Vendor-defined APIs) |
9. Implementation Guide: Sequencing
Critical path: You CANNOT skip to Layer 3 without 1A, 2A, 2B, and 2C.
| Phase | Layers | Key Deliverable |
|---|---|---|
| Phase 1: Foundation | Layer 1A, Layer 2A | Can provision GPU workloads with governed quotas |
| Phase 2: Runtime | Layer 1B, Layer 2B | Can serve models and execute RAG pipelines at scale |
| Phase 3: Reasoning | Layer 2C | Policy-driven placement working (Integrate 2C with 1A and 2A) |
| Phase 4: Applications | Layer 3 | Business value realized via autonomous agent workflows |
10. Cost Lens by Layer (ROI of Layer 2C)
Layer 2C is the Cost Governor because it is the only component that sees cost across all layers simultaneously.
Example: Multi-Objective Cost Optimization
| Metric | Without Layer 2C (Naive Routing) | With Layer 2C (Cost-Aware Routing) |
|---|---|---|
| Placement Logic | Routes to fastest available GPU (A100 in US) | Routes to sufficient GPU (A10 in EU) |
| Data Egress | $0.08/GB (from EU storage to US compute) | $0.00 (Local access in EU) |
| Cost per 1000 Requests | ~$2.50 | ~$1.20 |
ROI of Layer 2C: Layer 2C facilitates a 52% cost reduction by trading latency headroom for cost savings, all while meeting the SLA. This infrastructure autonomy provides a clear, defensible business justification for the Layer 2C investment.
11. Strategic Takeaways
For CTOs
Action 1: Challenge Vendor Claims
When a vendor pitches an “AI Platform,” ask: “Which layer is your Layer 2C?” If they cannot define the reasoning plane, they are selling you automation, not autonomy.
Action 2: Sequence Your Build
Do not fund Layer 3 agent applications until Layer 2C is deployed and integrated with Layer 1A governance.
Anti-pattern: Building Layer 3 agents before 2C exists leads to ungoverned autonomy, cost explosions, and compliance failures.
For Architects
Principle 1: Governance Enables Autonomy
Layer 2C only works if Layer 1A metadata is rich and accurate. Investment in the Data Plane (1A) must precede investment in the Reasoning Plane (2C).
Principle 2: Disaggregate for Agility
Replace monolithic “AI platforms” with best-of-breed components at each layer, defined by clear API contracts (See Appendix A).
Share This Story, Choose Your Platform!

Keith Townsend is a seasoned technology leader and Founder of The Advisor Bench, specializing in IT infrastructure, cloud technologies, and AI. With expertise spanning cloud, virtualization, networking, and storage, Keith has been a trusted partner in transforming IT operations across industries, including pharmaceuticals, manufacturing, government, software, and financial services.
Keith’s career highlights include leading global initiatives to consolidate multiple data centers, unify disparate IT operations, and modernize mission-critical platforms for “three-letter” federal agencies. His ability to align complex technology solutions with business objectives has made him a sought-after advisor for organizations navigating digital transformation.
A recognized voice in the industry, Keith combines his deep infrastructure knowledge with AI expertise to help enterprises integrate machine learning and AI-driven solutions into their IT strategies. His leadership has extended to designing scalable architectures that support advanced analytics and automation, empowering businesses to unlock new efficiencies and capabilities.
Whether guiding data center modernization, deploying AI solutions, or advising on cloud strategies, Keith brings a unique blend of technical depth and strategic insight to every project.


