The Operational Cost of AI: When Speed Becomes a Liability
revised 10/28/2025
TL;DR
In The Hidden Friction of GPU Adoption, we explored how GPUs add cost and complexity to enterprise operations.
This continuation examines why: the industry’s fixation on instantaneous speed.
GPU vendors sell throughput as strategy—implying that faster tokens mean competitive advantage. Enterprises absorb that story and overbuild for latency gains that rarely change business outcomes.
Speed becomes a liability when the incremental cost of acceleration exceeds the incremental business value it produces.
This piece clarifies when that happens and what to do about it.
How to Use This Post
-
Identify which of your AI workloads are latency-bound.
-
Use the LPM (Latency Penalty Multiplier) lens to decide if acceleration is paying for itself.
-
Apply the recovery and governance checklists to rebalance GPU spend.
1. Why Speed Feels Like Strategy
AI marketing has made speed the symbol of progress.
Every slide deck shows tokens per second, latency curves, and “real-time” pipelines as proof of innovation.
The problem isn’t that enterprises are naïve—it’s that vendor incentives and executive instincts align.
CTOs want to show readiness; vendors sell readiness in the form of hardware.
Speed feels like a safe bet—until the bill comes due.
2. When Speed Actually Wins
There are legitimate cases where latency equals money.
| Scenario | Why Speed Pays | Principle |
|---|---|---|
| Real-Time Fraud Detection | Every millisecond delay increases potential loss. | The window of decision is shorter than the time to compute. |
| Interactive AI (Chatbots, Copilots) | Response time drives engagement and conversion. | User experience degrades with delay. |
| Continuous or Adaptive Training | GPUs stay saturated; CapEx is fully amortized. | Utilization approaches 100 %; cost aligns with value. |
Pattern:
Speed delivers value only when delay directly destroys it—when latency and loss are coupled.
Everywhere else, faster compute only creates higher cost.
3. When Speed Becomes a Liability
In most enterprise AI, workloads are throughput-bound, not latency-bound.
Reports, analytics enrichment, and copilots don’t lose value because they finish in five minutes instead of two.
Speed becomes a liability when:
-
Utilization drops below 50 %.
-
Latency improvements stop influencing business KPIs.
-
Governance, security, or support overhead doubles to maintain performance.
The reflex to shave seconds from non-critical workflows inflates cost without improving outcomes.
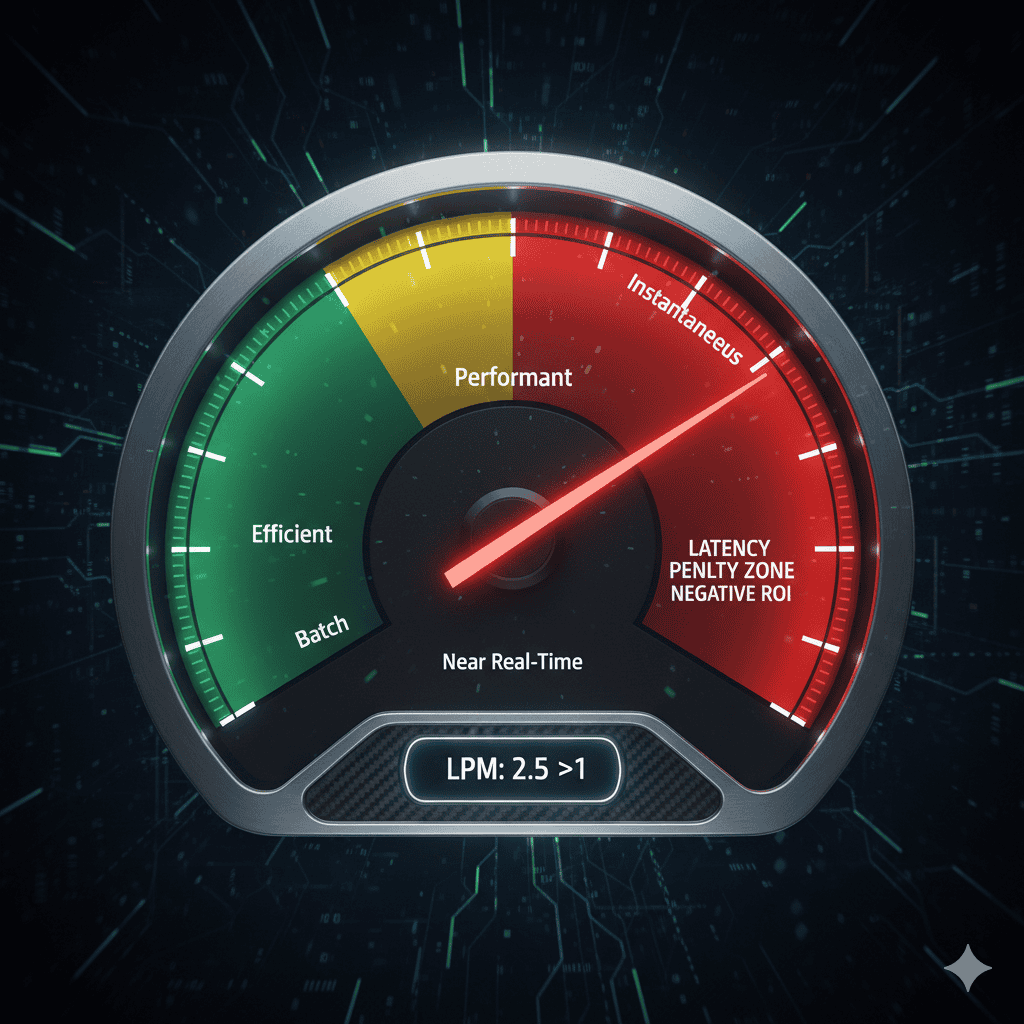
4. The Latency Penalty Multiplier (LPM)
A framework for recognizing diminishing returns:
LPM = Incremental Cost of Speed Gain ÷ Incremental Business Value of Speed Gain
Use LPM as a conversation tool, not a calculator.
It helps leadership frame the question: “Are we paying more for performance than it’s worth?”
Executives can proxy “business value” using existing metrics:
-
Revenue lost per minute of delay
-
Cost of operational downtime
-
Customer abandonment rates by latency tier
When additional cost rises faster than measurable impact, the LPM > 1 —and acceleration has turned counter-productive.
5. The Real Cost of Chasing Speed
| Driver | Common Decision | Consequence (Observed in practice) |
|---|---|---|
| “We need real-time analytics.” | Re-engineer pipelines for sub-second response. | Infrastructure spend jumps several-fold; utilization drops. |
| “We can’t afford lag.” | Adopt oversized models for small accuracy gains. | Inference cost rises; throughput stalls. |
| “We need future readiness.” | Buy GPUs ahead of demand. | Idle capacity becomes sunk cost before workloads arrive. |
These aren’t poor decisions—they’re defensive decisions made under pressure to appear modern.
But defensive speed often converts CapEx into unused potential.
Example: Fresh Farms’ GPU-Enabled VxRail
At a recent AI Field Day, the IT Director of Fresh Farms shared how adding GPUs to their VxRail environment delivered a 10× performance gain—but no measurable business lift. GPU utilization hovered below 20 percent while the team wrestled with driver alignment, patch cadence, and vSphere scheduling quirks. The infrastructure ran faster, but the business outcomes didn’t.
6. Counterpoint: The Case for Optionality
GPU headroom can create strategic flexibility—faster prototyping, model experimentation, and reduced procurement lag.
Optionality has value, but only when managed intentionally.
Middle-path options:
-
Burst to cloud during spikes.
-
Use spot instances for transient training.
-
Run hybrid: CPU for steady workloads, GPUs for bursts.
Optionality should expand capability, not justify idle capacity.
7. Executive Off-Ramps for Responsible Speed
CTOs can redirect “faster = better” conversations with a few pragmatic questions and tactics.
1. Quantify the Trade-Off
“Is cutting latency from 5 seconds to 1 second worth a 50 % budget increase?”
Tie every performance target to a revenue or risk metric.
2. Right-Size the Model
Distillation and quantization often deliver 90 % of the accuracy for a fraction of the cost.
3. Tier Latency Expectations
Define three service levels:
-
Tier 1 (Real-Time) — customer-facing, latency-sensitive
-
Tier 2 (Near Real-Time) — minutes matter
-
Tier 3 (Batch) — latency irrelevant
Reserve GPUs for Tier 1; run Tiers 2 and 3 on CPU or elastic capacity.
8. Organizational Realities and Politics
“GPU adoption” often doubles as organizational theater.
The CEO saw a demo; the AI team wants legitimacy; the board expects momentum.
Saying “no” to speed can feel like saying “no” to innovation.
CTOs can navigate this by separating symbolic readiness from operational readiness:
-
Stage proofs-of-concept in GPU-rich sandboxes.
-
Showcase wins without committing to permanent clusters.
-
Use utilization data from pilots to set procurement thresholds.
This satisfies visibility demands while preserving budget discipline.
9. If You’re Already Over-Provisioned
Many enterprises already have idle GPU farms.
The question isn’t guilt—it’s recovery.
Practical next steps:
-
Rebalance Workloads: Move inferencing or fine-tuning tasks from cloud to on-prem GPUs.
-
Virtualize and Share: Use GPU partitioning (vGPU/MIG) to increase utilization across teams.
-
Monetize or Offset: Offer internal GPU time to R&D units or external partners.
-
Reset the Narrative: Present current capacity as strategic optionality—then implement utilization KPIs going forward.
10. Translating Vendor Metrics into Enterprise Value
Vendors talk in throughput; enterprises live in outcomes.
This section helps translate the marketing pitch into operational reality.
| Vendor Claim | CTO’s Translation Question |
|---|---|
| “Our GPUs deliver 2× tokens per second.” | “Which workflow metric or KPI improves at that rate?” |
| “Always-on inference ensures readiness.” | “What utilization level justifies that standby capacity?” |
| “Bigger models mean accuracy.” | “Does that accuracy change a business decision?” |
Vendor metrics sell capacity. Enterprise metrics measure impact.
11. Speed Liability Diagnostic
A quick checklist for identifying when acceleration has crossed from asset to overhead:
-
GPU utilization below 50 % for more than a quarter
-
Latency reductions with no measurable KPI change
-
Support or compliance workloads doubled to sustain performance
-
Business units can’t articulate which KPI depends on sub-second latency
If two or more are true, you’ve likely entered the speed liability zone.
12. Strategic Takeaway
Acceleration is seductive but not always strategic.
CTOs should:
-
Challenge the assumption that faster is inherently better.
-
Use LPM as a framing tool to align spend with measurable benefit.
-
Apply off-ramps and tiering to control GPU creep.
-
Treat GPUs as HPC assets—specialized, measurable, and reserved for latency-critical work.
Speed is an asset only when it changes outcomes.
Otherwise, it’s operational debt wearing the mask of progress.
Share This Story, Choose Your Platform!

Keith Townsend is a seasoned technology leader and Founder of The Advisor Bench, specializing in IT infrastructure, cloud technologies, and AI. With expertise spanning cloud, virtualization, networking, and storage, Keith has been a trusted partner in transforming IT operations across industries, including pharmaceuticals, manufacturing, government, software, and financial services.
Keith’s career highlights include leading global initiatives to consolidate multiple data centers, unify disparate IT operations, and modernize mission-critical platforms for “three-letter” federal agencies. His ability to align complex technology solutions with business objectives has made him a sought-after advisor for organizations navigating digital transformation.
A recognized voice in the industry, Keith combines his deep infrastructure knowledge with AI expertise to help enterprises integrate machine learning and AI-driven solutions into their IT strategies. His leadership has extended to designing scalable architectures that support advanced analytics and automation, empowering businesses to unlock new efficiencies and capabilities.
Whether guiding data center modernization, deploying AI solutions, or advising on cloud strategies, Keith brings a unique blend of technical depth and strategic insight to every project.