AWS vs. NVIDIA DGX: The Real Platform Divide
In the run-up to AWS re:Invent, the conversation followed a predictable pattern:
Trainium vs. NVIDIA.
Price-performance. FLOPs. Benchmarks.
That’s the easy story to tell.
But inside enterprise strategy sessions, no one is asking me about Trainium’s training performance or whether it threatens Blackwell.
The real question enterprises are wrestling with is simpler and more fundamental:
“What platform am I building on as inference becomes my primary AI workload?”
This is the shift that matters. The Inference Flip.
And once you look at the world through that lens, the AWS vs. NVIDIA question stops being about hardware.
It becomes a question of whether you intend to build a platform or consume one.
We’ve Seen This Before: The Graviton Lesson
Graviton didn’t beat Intel and AMD by being “faster x86.”
Graviton won because AWS made the underlying silicon irrelevant to most workloads.
Teams adopted Graviton without caring about what instruction set it ran on.
The chip simply stopped being a decision point.
That’s the same move AWS is making with AI infrastructure.
Most enterprises aren’t optimizing CUDA kernels or building custom inference runtimes.
They’re trying to run safe, governed AI systems across their business.
For them, the question isn’t:
“Is DGX faster?”
It’s:
“Do I want to care about the layer underneath the abstraction?”
A Fortune 100 architect summed it up perfectly during a recent call:
“We don’t want to be in the business of managing GPUs.”
And that sentence essentially defines AWS’s strategy.
The Inference Flip Changes the Platform Equation
Training workloads sit comfortably in the land of specialized clusters and controlled environments.
Inference is different because it must run inside everything an enterprise already operates:
-
IAM and identity boundaries
-
Data governance
-
Network security
-
Existing workflows and APIs
-
Cost controls
-
Operational SLAs
Inference isn’t just model execution.
It’s reasoning, decision-making, policy enforcement, integration, and auditability.
Through the lens of the 4+1 Layer AI Infrastructure Model:
-
Training = Layer 0 + Layer 2B
-
Inference at scale = Layer 2C + Layer 3
And Layer 2C is exactly where AWS is investing.
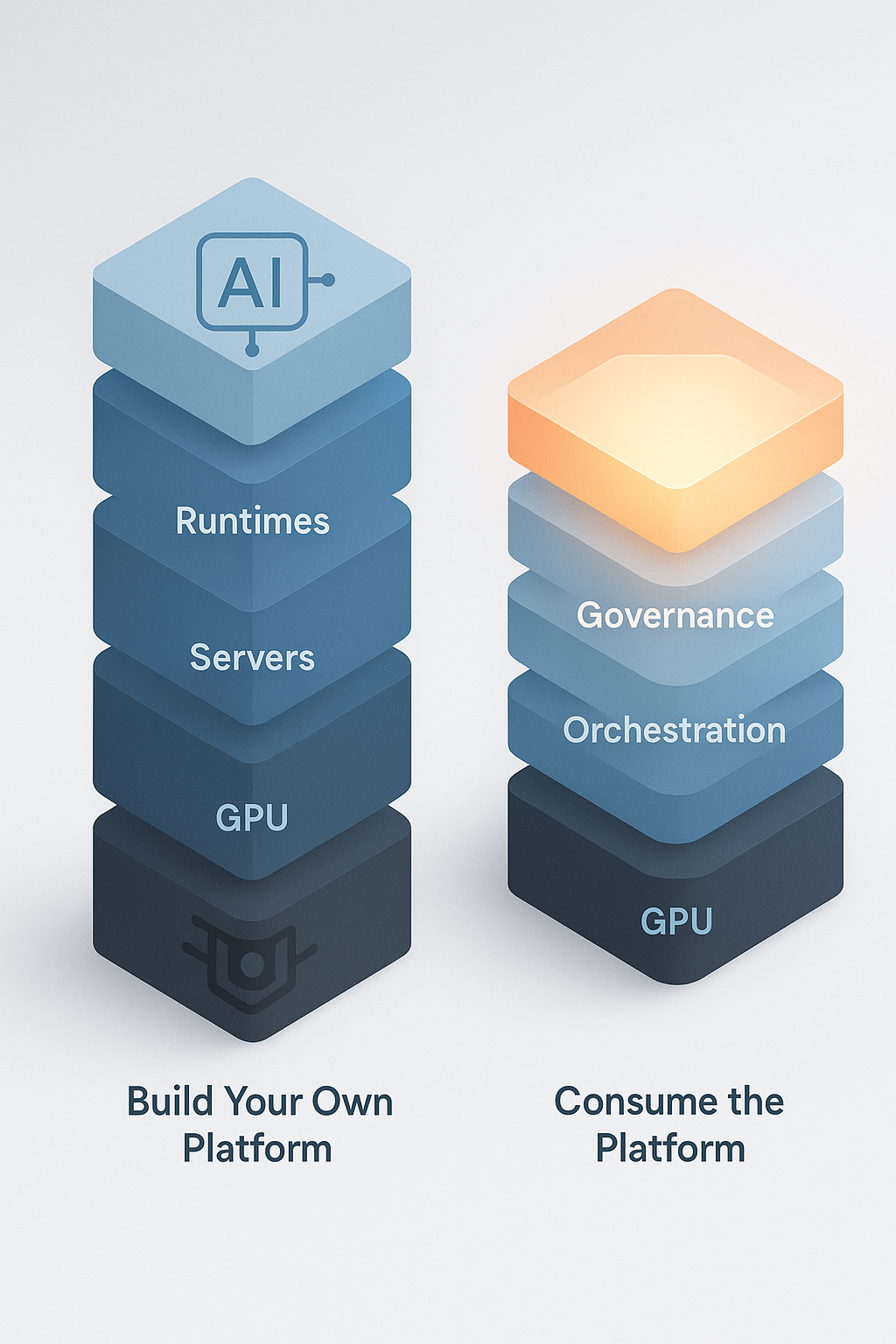
NVIDIA DGX: The Build-Your-Platform Path
DGX is not “just GPUs.”
It’s a vertically integrated inference execution system:
-
GPU hardware
-
CUDA
-
Triton
-
TensorRT
-
tightly controlled runtime behavior
DGX gives you the best environment in the world to execute models at scale.
If you want to build your own AI platform — your own orchestration, your own reasoning layer, your own data governance and policy stack — DGX is the right foundation.
DGX dominates the lower half of the stack:
-
Layer 0: Compute
-
Layer 2B: Model Execution Runtime
But DGX doesn’t try to be:
-
a reasoning engine
-
an agent governance layer
-
a multi-agent orchestrator
-
a policy enforcement system
That is by design.
DGX is for organizations who want to own the platform layer.
AWS: The Consume-the-Platform Path
AWS is not trying to displace NVIDIA in the hardware execution layer.
If anything, they lean into it — AWS deploys massive fleets of NVIDIA systems internally.
Instead, AWS is building the layers above GPU execution:
-
AgentCore Policies (governance and guardrails)
-
Evaluations (correctness and safety)
-
Episodic Memory (reasoning context)
-
Planning and orchestration primitives
-
Bedrock Attachments (secure data access inside reasoning chains)
-
Managed multi-agent runtimes
None of this is about making inference faster.
It’s about making inference usable in production.
This is Layer 2C — the Reasoning Plane.
AWS is building a platform for enterprises who want to consume intelligence, not assemble it.
So What Are Enterprises Actually Choosing?
When you strip away the noise, the decision looks like this:
Path 1: Build your own AI platform
→ DGX underlay
→ You own orchestration, governance, and reasoning
→ Maximum control, maximum complexity
Path 2: Consume a managed AI platform
→ AWS Bedrock + AgentCore
→ You abstract the GPU layer
→ You focus on application intelligence, not infrastructure
Path 3: Hybrid
→ DGX for raw execution
→ AWS for reasoning and orchestration
→ Likely the long-term reality for large enterprises
This is why AWS isn’t competing with DGX.
They’re building on top of DGX.
Just like they built on top of x86 when launching Graviton.
The question is no longer:
“Which GPU is faster?”
The question is:
“Which parts of the AI platform do I want to own, and which parts do I want AWS to abstract away?”
The Platform Decision That Actually Matters
Enterprises don’t win the Inference Flip because they pick the fastest accelerator.
They win because they build on a platform that lets them:
-
govern reasoning
-
control data boundaries
-
coordinate agents
-
integrate with existing systems
-
scale autonomy safely
-
reduce operational friction
These are not hardware questions.
They are platform questions.
DGX gives you the engine.
AWS gives you the operating environment.
And the modern enterprise needs both — but not in equal proportions.
The strategic decision is where you want the center of gravity of your AI platform to live:
-
in the GPU layer you manage
-
or the reasoning layer AWS manages for you
That’s the real AWS vs. DGX divide.
And it has very little to do with Trainium 5 vs. NVIDIA.
Share This Story, Choose Your Platform!

Keith Townsend is a seasoned technology leader and Founder of The Advisor Bench, specializing in IT infrastructure, cloud technologies, and AI. With expertise spanning cloud, virtualization, networking, and storage, Keith has been a trusted partner in transforming IT operations across industries, including pharmaceuticals, manufacturing, government, software, and financial services.
Keith’s career highlights include leading global initiatives to consolidate multiple data centers, unify disparate IT operations, and modernize mission-critical platforms for “three-letter” federal agencies. His ability to align complex technology solutions with business objectives has made him a sought-after advisor for organizations navigating digital transformation.
A recognized voice in the industry, Keith combines his deep infrastructure knowledge with AI expertise to help enterprises integrate machine learning and AI-driven solutions into their IT strategies. His leadership has extended to designing scalable architectures that support advanced analytics and automation, empowering businesses to unlock new efficiencies and capabilities.
Whether guiding data center modernization, deploying AI solutions, or advising on cloud strategies, Keith brings a unique blend of technical depth and strategic insight to every project.


